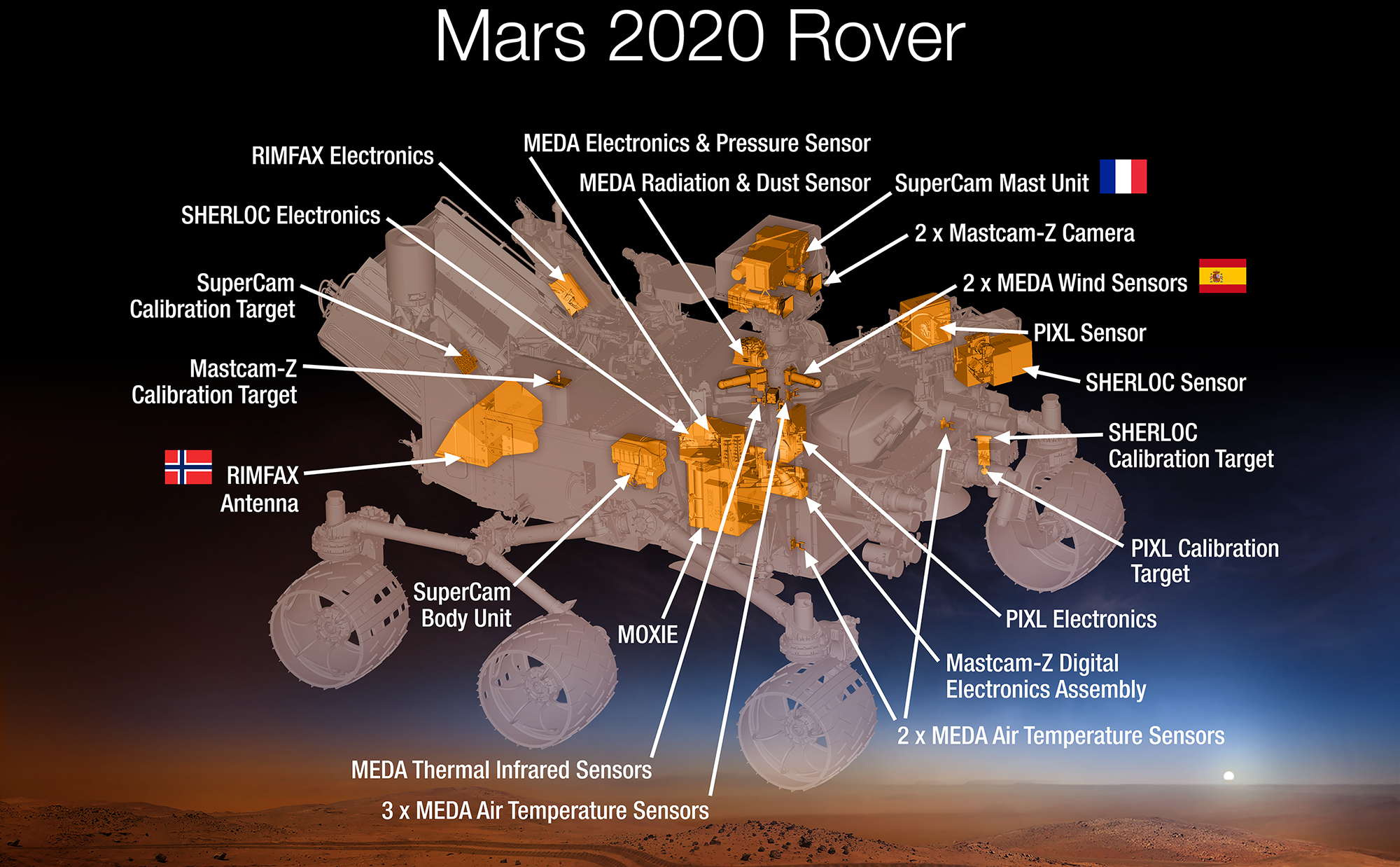
The Copyright Laws of the United States recognizes a “fair use” of copyrighted content. Section 107 of the U.S. Copyright Act states: “Notwithstanding the provisions of sections 106 and 106A, the fair use of a copyrighted work (...) for purposes such as criticism, comment, news reporting, teaching, scholarship, or research, is not an infringement of copyright.” Any image or video posted is used according to the fair use policy
Ogni newsè tratta da articoli peer reviewed ed è contestualizzata e collegata a fonti di approfondimento. Ben difficilmente troverete quindi notizie il cui contenuto sia datato. QUALUNQUE link in questa pagina rimanda a siti sicuri!! SEMPRE. Volete aiutare questo blog? Cliccate sugli annnunci/prodotti Amazon (se non li vedete, disattivate l'Adblocker mettendo questo sito nella whitelist. NON ci sono pop up o script strani, SOLO Amazon). Visibili in modalità desktop!
Se poi decidete di comprare libri o servizi da Amazon, meglio ;-) Dimenticavo. Questo blog NON contiene olio di palma (è così di moda specificarlo per ogni cosa...)
La NASA ha annunciato che la sonda che verrà lanciata verso Marte tra meno di due anni, trasporterà oltre all'ormai classico rover anche un piccolo elicottero a guida autonoma.
Ammetto che l'idea di vedere un elicottero solcare i cieli marziani è molto intrigante, tale da trasportarci in scenari da film di fantascienza. La realtà sarà tuttavia un poco diversa data la tipologia di elicottero, il cui progetto ha dovuto tenere conto di tre variabili chiave: trasporto fino al pianeta; atmosfera marziana; "guidabilità" e autonomia.
Quindi sommando la necessità di peso ridotto e dimensioni contenute, il prototipo prescelto avrà la dimensione di un mini-drone
Atmosfera
L'atmosfera marziana è ben diversa da quella terrestre sia in termini qualitativi che quantitativi. In assenza di ossigeno ogni ipotesi di motore a combustione viene meno (anche se ci fosse una stazione di rifornimento sulla superficie) ma quello che più importa qui è la minore pressione atmosferica (quindi densità dell'aria); la pressione atmosferica marziana è circa l'1% di quella terrestre alla superficie. Non bisogna essere ingegneri aeronautici per capire come la portanza di un velivolo in tali condizioni sia problematica, equivalente a quella di un velivolo a 30 mila metri di quota sulla Terra. Dato che l'altezza maggiore mai raggiunta da un elicottero è di circa 12 km, volare su Marte comporta problemi aerodinamici del tutto nuovi.
L'elicottero(-ino) dovrà essere capace di volo autonomo e di una certa autonomia. La distanza dalla Terra impedisce un controllo in tempo reale (serve qualche minuto per fare arrivare il segnale) quindi dovrà essere capace di fare autocorrezioni; non ci sarà nessuno che possa andarlo a recuperare in caso di energia esaurita, ragione per cui dovrà sempre usare il rover come punto di riferimento.
Stante le problematiche, i ricercatori del Jet Propulsion Laboratory della NASA sono stati a lungo indecisi se aggiungere o meno il drone al carico principale, la nuova versione del rover marziano. E' di inizio maggio la decisione che il vantaggio potenziale di ottenere una visione a "volo d'uccello" della superficie marziana supera il rischio di un drone incapace di librarsi in quell'atmosfera; alla peggio la missione verterà, come previsto all'inizio, sul rover.
Come potrebbe apparire il mini elicottero sulla superficie marziana (credit: NASA/JPL)
Il mini-elicottero avrà dimensioni contenute (1 metro) e un peso (sulla Terra) di soli 1,8 kg. Le pale ruoteranno circa 10 volte più velocemente di quello che sarebbe necessario qui, proprio per la necessità di creare uno spostamento d'aria sufficiente a tenerlo in volo in una atmosfera rarefatta. Dove alloggiarlo è stato un'altra scelta complicata; deve essere protetto ma facilmente sganciabile dalla sonda Mars 2020.
Come si prevede avverrà "l'atterraggio" del rover sulla superficie
Gli ingegneri del JPL hanno optato per la parte laterale del rover in modo che sia facilmente sganciabile dopo l'avvenuto contatto con il suolo. Il piano prevede almeno cinque voli autonomi nei primi 30 giorni con una autonomia di qualche minuto.
Di seguito il video descrittivo rilasciato dalla NASA
Non ho mai amato la sauna in nessuna delle sue declinazioni, forse perché già mi basta l'afosa estate padana. Tuttavia se già i romani ne facevano ampio uso insieme alle terme, considerate il vero segno distintivo rispetto ai barbari, abitudine poi mutuata sia dagli ottomani che dai finlandesi (qui associata al successivo bagno gelato), è innegabile ipotizzare benefici che vanno oltre la componente igienica.
Sauna finlandese (credit:CC BY-SA 3.0/wikipedia)
La scienza ha investigato negli anni i pro e i contro di tale pratica identificando nelle patologie vascolari (anche solo la presenza di varici venose nelle gambe) quei casi in cui la sauna è sconsigliata. Per il resto, se fatta in modo corretto, sembra confermata l'azione tonica cardiovascolare.
Uno studio recente aggiunge un tassello importante, con la osservazione che la sauna riduce del 61 % il rischio cumulativo di ictus nelle persone che ne fanno un uso almeno quotidiano. La ricerca, condotta in Finlandia da una equipe anglo-finnica, è consistita in un follow-up durato 15 anni di coloro che facevano una sauna tra le quattro e le sette volte a settimana, confrontate con chi la faceva una volta a settimana.
Si tratta del primo studio su larga scala su questo argomento e i risultati sono stati pubblicati sulla rivista Neurology.
Il tema è particolarmente importante se si considera che l'ictus è una delle principali cause di disabilità nei paesi sviluppati, che innesca importanti ricadute economiche ed umane sulla società (dall'assistenza sanitaria all'impatto sulla famiglia, passando per mancata produttività e costi vari).
Lo ricerca è avvenuta nell'ambito del Kuopio Ischemic Heart Disease Risk Factor (KIHD), uno studio prospettico centrato sulla popolazione finlandese. Nello specifico, i ricercatori hanno estratto i dati di 1628 individui (uomini e donne) di età compresa i 53 e i 74 anni che vivono nella parte orientale della Finlandia, associando la loro frequenza di utilizzo della sauna (la versione finlandese con umidità relativa intorno al 10-20%) con il loro stato di salute nel corso degli anni. Quello che è emerso è che maggiore era la frequenza della sauna, minore era il rischio di ictus. Le persone sono stati suddivise in tre gruppi in base alla frequenza: una volta; due-tre volte e tra quattro e sette volte a settimana.
Rispetto a quelli del primo gruppo, i soggetti del secondo e terzo gruppo hanno un rischio di ictus inferiore del 14% e del 61%, rispettivamente. Tale associazione si mantiene anche dopo normalizzazione per fattori come età, sesso, indice di massa corporea, diabete, consumo di alcol, attività fisica e status socio-economico; un dato che indica l'esistenza di una azione protettiva della sauna, prevalente su altri fattori di rischio.
Non è il primo studio ad avere osservato un tale effetto. Sempre nell'ambito del KIHD si era osservato che la sauna riduceva significativamente sia il rischio di mortalità cardiovascolare che quello generale.
Secondo i ricercatori, i meccanismi alla base di tale effetto protettivo sono una somma di riduzione della pressione sanguigna (diminuita rigidità delle pareti arteriose), una stimolazione del sistema immunitario, un impatto positivo sul sistema nervoso autonomo e in generale una migliore funzionalità cardiovascolare.
Quasi, quasi comincio anch'io a frequentare le saune.
Fonte
- Sauna bathing reduces the risk of stroke in Finnish men and women: A prospective cohort study
Dopo un'attesa febbrile, gli astronomi di tutto il mondo hanno una galassia di nuovi dati da analizzare. Il 25 aprile infatti, l'Agenzia spaziale europea (ESA) ha reso disponibili i dati catturati nell'ambito della missione Gaia e con essi la prima mappa completamente 3D della Via Lattea.
La sonda Gaia scruta la nostra galassia
Non parliamo di una "semplice" istantanea della galassia, seppure ad alta risoluzione. E' molto ma molto di più. La mappa definisce la posizione di circa 1,7 miliardi di stelle con in più, per circa 1,3 miliardi di esse, le distanze relative, i colori, la velocità e la direzione del loro movimento.
Credit: ESA/Gaia/DPAC
L'insieme dei dati permette di creare un mappa in movimento del cielo senza precedenti, capace di coprire un volume 1000 volte volte più grande di quello finora disponibile.
La presentazione del catalogo di Gaia è stata fatta da Gerry Gilmore dell'università di Cambridge, che ha mostrato una simulazione del movimento (futuro) di milioni di stelle.
La missione è centrata sul satellite Gaia, una sonda da 2 tonnellate lanciata alla fine del 2013 e divenuta operativa a partire dal luglio 2014 dopo aver raggiunto la posizione predefinita. Gaia è attualmente in una orbita stabile e fissa rispetto alla posizione del Sole e della Terra a circa 1,5 milioni di km da noi, con un grado di precisione dell'ordine di 150 metri.
Esistono diversi punti orbitali in cui è possibile mantenere una sonda può rimanere stabile rispetto a Sole e Terra, definiti come Punti di Lagrange. Gaia si trova nel punto L2.
La strumentazione di bordo contiene 2 telescopi identici del tipo Astro (con integrato sistema di elaborazione immagini), fotometri per lunghezze d'onda del blu e del rosso, e infine uno spettrometro. Gli strumenti effettuano misurazioni ripetute dal confronto delle quali diventa possibile misurare la distanza stellare grazie alla tecnica nota comeparallasse.
Tra i dati più attesi vi è la misurazione delle distanze reali di determinati tipi di stelle, note come stelle variabili, usate in astronomia come degli standard di riferimento. Conoscere la posizione (e distanza) esatta di queste stelle nella Via Lattea è un punto ineludibile per misurare "oggetti" posti a distanze molto maggiori. Oltre che per mappare oggetti più distanti, queste stelle standard sono utilizzate per ottenere una stima della velocità di espansione dell'universo.
La necessità di ottenere standard più precisi è sorta con la scoperta che alcuni dati ricavati con questa tecnica "di riferimento" non coincidevano con quanto ricavato dalle mappe della radiazione cosmica di fondo (un residuo ancora oggi visibile del Big Bang). La maggior precisione delle misurazioni effettuate da Gaia dovrebbero, nelle attese degli astrofisici, contribuire a risolvere tali discrepanze analitiche.
Un altro campo in cui Gaia promette grandi cose è la ricerca dei sistemi planetari extrasolari. Un campo questo che ha visto enormi progressi negli ultimi 10 anni, evidente nel risultato di avere identificato e catalogato 3725 nuovi pianeti (--> articoli precedenti e tag --> "esopianeti"). I metodi di indagine non saranno diversi da quelli oggi in uso, come il microlensing e astrometria, ma il maggior dettaglio dei movimenti stellari aumenterà il grado di risoluzione, permettendo di scoprire pianeti più piccoli e simili (almeno come posizione e caratteristiche) alla Terra.
Ma forse la maggior attesa è quella legata alla rilevazione delle mini oscillazioni in grado di segnalare le onde gravitazionali e alla mappatura degli asteroidi, identificando con largo anticipo quelli potenzialmente pericolosi per il nostro pianeta (la storia insegna che è già capitato e capiterà ancora che un asteroide di tal tipo colpisca la Terra).
Nonostante un errore tecnico verificatosi a febbraio, che ha mandato Gaia in "modalità provvisoria" fino al ripristino, la sonda gode di buona salute. Salvo inconvenienti tecnici (o urti con mini asteroidi) Gaia ha abbastanza energia per continuare la sua missione a tutto il 2024. Un tempo sufficiente per essere inondati di dati utili per il lavoro di migliaia di scienziati.
Nel precedente articolo abbiamo visto come sia possibile archiviare l'informazione digitale (e quindi anche analogica digitalizzata) sotto forma di DNA e quali vantaggi offra (--> DNA come pendrive del futuro).
Rimaniamo sul tema parlando del progetto #MemoriesInDNA il cui fine, come dice il nome, è quello di archiviare le proprie foto (o qualunque immagine si ritiene debba essere conservata) nel DNA, a beneficio della scienza e delle generazioni future.
Se uno potesse scegliere quale immagine conservare per migliaia di anni, avrebbe l'imbarazzo della scelta. Potrebbe essere la foto della sua famiglia, un paesaggio a rischio, una istantanea fatta in un momento irripetibile o anche la pagina di un libro di poesie. Sarebbe come mettere l'informazione in una bottiglia di vetro immaginaria e lasciarla galleggiare nell'oceano del tempo fino al suo approdo in una spiaggia del futuro dove verrebbe rimirata dai nostri discendenti.
Ovviamente perché questo sia fattibile è fondamentale immaginare una discendenza tecnologicamente capace di analizzare il DNA e non regredita (come immaginato da HG Wells) in una umanità selvaggio-bucolica.
I ricercatori dell'Università di Washington (UW), in collaborazione con la Twist Bioscience, hanno cominciato a raccogliere 10 mila immagini originali da tutto il mondo con lo scopo di immagazzinarne l'informazione sotto forma di DNA sintetico.
Ma il progetto è aperto a tutti. Chiunque voglia inviare fotografie originali che ritiene meritevoli di essere tramandate (anche solo perché importanti per chi le ha scattate le può caricate sul sito del consorzio
(http://memoriesindna.com/) oppure mediante Twitter usando l'hashtag
#MemoriesInDNA.
Alcune delle immagini salvate
(all credit to: University of Washington)
Nota. Per essere inclusi nella raccolta di immagini DNA, le fotografie non possono essere protette da copyright e devono essere prive di contenuti violenti o inappropriati. Il set di dati dell'immagine sarà conservato nel DNA indefinitamente e condiviso con ricercatori di tutto il mondo. Per ulteriori informazioni vi rimando al sito #MemoriesInDNA Project.
Archiviare la massa di dati digitali come DNA è vista dai ricercatori come la soluzione per colmare il divario tra la quantità di dati digitali generati oggi - da qualsiasi cosa, dai video commerciali alle immagini spaziali alle cartelle cliniche - e la nostra capacità di archiviali in modo economico, efficiente e soprattutto duraturo.
A differenza dei data center, che richiedono molto spazio e risorse (sia come strutture che energetiche, circa il 2% del consumo totale di elettricità negli Stati Uniti) le molecole di DNA possono memorizzare le stesse informazioni con un risparmio di spazio di milioni di volte. Il processo di base è concettualmente semplice e si basa sulla conversione delle stringhe di "1" e "0" digitali nei quattro elementi costitutivi fondamentali delle sequenze di DNA (le basi adenina, guanina, citosina e timina). Il passaggio ovviamente deve bidirezionale, cioè è necessario che dal DNA sia possibile recuperare in modo univoco l'informazione digitale per ricostruire l'immagine.
I ricercatori della UW e della Twist Bioscience sono esperti in questo processo, non a caso detengono il record mondiale per la quantità di dati memorizzati nel DNA.
Con l'accumularsi delle immagini "stoccate" nel DNA la sfida che attende i ricercatori è quella di identificare facilmente una o più immagini "di interesse" sfruttando dei "tag" (etichette) identificative.
Ipotizziamo ad esempio che ci sia un trilione di immagini codificate nel DNA e che tu voglia recuperare solo quelle fotografie che mostrano una macchina rossa oppure se c'è il volto di una persona (e magari quale). Per poterlo fare è necessario che quelle informazioni siano contenute (e recuperabili) nel DNA come mini indici riassuntivi. Anche in questo caso "come farlo" non è difficile da immaginare una volta che si tiene presente che il DNA è costituito da una doppia elica complementare e antiparallela
In termini semplici la sequenza su una elica determina quella dell'altra per ragioni di complementarietà delle basi. La "A" si appaia con la "T" e la "C" con la "G"). Quindi nell'informazione digitale si introducono delle sequenze che definiscono "auto" e "rosso", sarà possibile produrre delle mini sequenze di DNA specifiche per queste due informazioni, con le quali andare a "catturare" solo le immagini idonee. Ancora una volta il modo per "catturare" il DNA utile non è complesso; se le sequenze "esca" a singola elica vengono associate a nanoparticelle magnetiche e queste vengono poi mischiate al DNA del "database", sarà sufficiente usare un magnete per estrarre il DNA bersaglio "utile" che si sarà "appaiato" al DNA esca, e quindi procedere all'analisi dell'informazione.
Questo è solo un esempio minimo di quello che i ricercatori vogliono fare. Algoritmi di intelligenza artificiale cercheranno di ricavare le informazioni per indicizzare tutte i dati presenti in una data fotografia, come i colori, la presenza di linee, curvature, oggetti, ... . Del resto si tratta di informazioni che sono già presenti nel file digitale e che di conseguenza sono presenti anche nel DNA sintetico. Diventerà così possibile capire subito dall'analisi di un petabyte di informazioni (meno di un grammo di DNA, che seccato equivale ad un piccolo deposito biancastro sul fondo di una provetta) se in quello stock di immagini ci sono (ad esempio) più macchine rosse o blu in una fotografia, se ci sono persone e se sono a piedi o in bicicletta, etc etc.
L'interesse da parte di finanziatori e istituzioni non manca. La UW ha ricevuto recentemente circa 6,3 milioni di dollari di finanziamento per implementare il processo rendendolo sempre più veloce e soprattutto facilmente "leggibile".
La crescita esponenziale dei dati generati in ambito scientifico ha un rovescio della medaglia, cioè come immagazzinarli in modo sicuro e duraturo.
Il solo CERN ad esempio ha prodotto più di 100 petabyte di dati che devono essere archiviati e resi accessibili non solo per l'immediato ma soprattutto per le future generazioni di ricercatori. Tuttavia i supporti standard per l'archiviazione di dati, come dischi ottici, dischi rigidi e nastri magnetici, hanno una durata variabile ma sempre nell'ordine di anni, se conservati adeguatamente.
Facile capire quindi l'importanza della ricerca di migliori tecnologie di archiviazione dei dati. Se dobbiamo cercare il meglio perché non guardare al miglior sistema di codifica e di preservazione dell'informazione di quello sviluppato dalla Natura circa 3,8 miliardi di anni fa con la comparsa della vita sotto forma di cellule? E se parliamo di cellule e di informazione codificata ci riferiamo al DNA (--> Nota 1 a fondo pagina).
Il DNA, la molecola che codifica le informazioni biologiche, ha il pregio di avere una notevole stabilità (può conservarsi per millenni) e la capacità di immagazzinare informazioni con alto rapporto informazione/densità (può codificare l'equivalente di petabytes di informazioni per grammo).
Lo spunto per l'odierno articolo viene da un lavoro pubblicato su Nature Biotechnology da Lee Organick e colleghi in cui si descrive un metodo per archiviare 200 megabyte di informazioni digitali sotto forma di DNA e di come recuperare tali informazioni senza errori "di lettura".
L'idea non è nuova.
Fin dagli anni '60, quando dopo la definizione della struttura del DNA da parte di Watson, Crick, Franklin e Wilkins i ricercatori scoprirono il modo con cui l'informazione era codificata (sappiamo oggi che quello era solo il primo livello), gli ingegneri informatici cominciarono a sognare di sfruttare tale sistema per immagazzinare i dati (anche analogici come il testo di un libro) codificandolo sotto forma di DNA (--> Nota 2)
A prima vista, la memorizzazione delle informazioni nel DNA appare semplice. Le informazioni digitali, una serie di 0 e 1 nota come "bit", possono essere facilmente rappresentate come una combinazione di nucleotidi. Ad esempio la sequenza 00-01-10-11 potrebbe essere definita dalla sequenza A-C-G-T, facilmente sintetizzabile.
Ma le informazioni digitali possono essere lunghe milioni di bit e la tecnologia attuale pur essendo diventata capace di leggere un genoma (ordine di grandezza gigabasi), previo spezzettamento per la lettura e riassemblaggio mediante algoritmi, ha un limite nella lunghezza delle molecole di DNA sintetizzabili ex novo (100-200 nucleotidi), cioè non partendo da una copia preesistente.
Vero che questi oligonucleotidi potrebbero essere uniti in una fase successiva a formare molecole più lunghe ma tale approccio non è ad oggi utilizzabile su larga scala. Pertanto, se si volesse usare il DNA come archivio di una informazione digitale, la moltitudine di frammenti separati dovrebbe essere in qualche modo essere leggibile in modo univoco; l'unico modo per farlo sarebbe indicizzare ciascun frammento in modo che l'ordine "di lettura" sia poi facile da ricavare.
Due, quindi, i problemi da affrontare: la scrittura (sintesi di frammenti lunghi o almeno indicizzabili) e la lettura (cioè il sequenziamento).
Sebbene i costi attuali del sequenziamento su larga scala siano una mera frazione dei costi di inizio duemila (l'attuale centinaio di dollari e un operatore necessario contro il miliardo speso per il sequenziamento del primo genoma umano, condotto da un consorzio pubblico e dalla azienda fondata da Craig Venter, per un totale di migliaia di persone coinvolte), il costo ed i tempi sono ancora multipli rispetto al costo di un supporto digitale (vedi sotto)
Il costo per sequenziare un genoma è oggi esiziale rispetto ad inizio millennio.
A questi problemi pratici si aggiunge un dato non secondario, quello della affidabilità della lettura. Il sequenziamento può non essere sempre univoco, specialmente in corrispondenza di sequenze ricche di C e G, oppure a causa di alterazioni locali; ad esempio la deaminazione spontanea della base C (citosina), fa si che la base modificata venga letta come U (uracile) cioè la base T presente nel RNA causando quindi una mutazione). Per evitare gli errori di lettura della sequenza è necessaria quindi una certa ridondanza della informazione in modo che un eventuale errore venga riconosciuto come tale e neutralizzato. Chiaramente creare ridondanza diminuisce la densità di informazione "utile" a parità di quantità DNA usato.
Ridondanza vuol dire aumentare il numero di molecole di DNA utilizzate e questo rinforza la necessità di sviluppare un sistema di indicizzazione dell'informazione presente (ma dispersa) in una singola provetta.
Nel 2017 (Erlich et al, Science v355) si era riusciti a sviluppare una ridondanza ed un algoritmo di rilevazione errori (quindi di discordanza e di identificazione della informazione corretta) sufficientemente potenti da permettere di archiviare 215 petabyte di informazioni in 1 grammo di DNA. Sebbene il risultato fosse un deciso miglioramento (di almeno 1 ordine di grandezza) rispetto ai precedenti, il metodo aveva un punto debole fondamentale: per estrarre l'informazione di una parte anche minima in essa era necessario "leggere" l'intero archivio.
E' come se volendo leggere la prima terzina del canto X dell'Inferno di Dante, uno dovesse leggere (anche se a velocità supersonica) l'intera Divina Commedia fino a incappare nella frase cercata. O anche leggere un intero disco rigido prima di trovare il file cercato. In un certo senso è quello che capita con i bambini quando si chiede loro di iniziare a recitare la poesia imparata a memoria da una strofa centrale mezzo; per farlo partono dall'inizio.
Proprio su questo punto critico ha lavorato il team di Organick riuscendo infine a trovare il modo di archiviare nel DNA e recuperare con successo (e senza "letture inutili") 200 megabyte di dati.
200 MB potranno sembrare risibili per le necessità attuali ma tutto deve essere contestualizzato nell'ambito di una tecnologia emergente. Per mettere tutto in prospettiva, ricordiamoci che il primo disco rigido sul mercato, sviluppato da IBM negli anni '50, era in grado di memorizzare circa 4 megabyte su un dispositivo che pesava più di una tonnellata! Ancora a fine anni 80 il disco rigido fantascientifico a cui uno poteva ambire era di qualche decina di MB)
Senza entrare troppo in termini tecnici, per i quali vi rimando all'articolo, ciascun frammento su cui è stata codificata l'informazione digitale è stato legato a "primer" univoci (corte sequenze di DNA, come fossero etichette) in modo che sia possibile, quando necessario, recuperare l'informazione ricercata facendo una sequenza a partire "dall'etichetta" cercata. Nello specifico del lavoro i ricercatori hanno convertito 35 file digitali in un totale di circa 13,5 milioni nucleotidi di DNA suddivisi in frammenti di 150 nucleotidi; il DNA totale è comprensivo della ridondanza interna come sistema di rilevazione degli errori.
Il principio dell'organizzazione dell'informazione sviluppato nel lavoro di Lee Organick
(credit: Organick et al, 2018)
Il risultato è molto importante anche se non possiamo nasconderci le molte sfide che devono ancora essere superate, tra tutte il costo complessivo e la velocità per recuperare l'informazione.
Il costo attuale per la memorizzazione di un singolo megabyte di dati nel DNA è dell'ordine di un centinaio di dollari, contro meno di 0,0001 $ per anno usando i classici nastri magnetici (in uso nei mega datacenter). Ovviamente il prezzo dell'archiviazione del DNA diminuirà in modo sostanziale al diminuire dei costi di sintesi e di lettura ma questo difficilmente avverrà nella stessa misura per quanto riguarda i tempi dell'analisi. "Scrivere" o "leggere" il DNA è intrinsecamente più lento rispetto al digitale (i millisecondi dei dischi rigidi) per non parlare dell'infrastruttura necessaria, ma questo non è necessariamente un problema se lo scopo è creare archivi di lungo termine e non per la consultazione quotidiana
Con il miglioramento delle tecnologie fondamentali, la molecola che codifica tutte le informazioni biologiche potrebbe diventare un giorno un mezzo robusto, compatto e affidabile per l'archiviazione digitale.
Fonte - Random access in large-scale DNA data storageRandom access in large-scale DNA data storage Lee Organick et al, (2018) Nature Biotechnology, 36, pp242–248
***
Nota 1. Da un punto di vista biologico è stato verosimilmente l'RNA il primo depositario di una informazione codificata e trasmissibile e solo in un secondo momento la selezione ha preferito "traslocare" l'informazione sul più stabile DNA. Non a caso molti virus sono basati solo sul RNA.
Nota 2. Rimanendo al primo livello di complessità (trascurando quindi regolazione trascrizionale ed epigenetica), l'informazione genica è
codificata da una sequenza di nucleotidi (A, C, G e T) letti come
triplette non sovrapposte, delimitate da un segnale di inizio e da uno di
termine (tre sono le possibili triplette di "STOP messaggio"). Le triplette
possibili sono 64 (43) di cui 61 sono "codificanti", cioè definiscono
quale aminoacido dovrà essere inserito durante la sintesi di una data
proteina (un gene codifica l'informazione per una proteina). Visto che
gli aminoacidi sono 20 e le triplette "utili" 61 ne consegue che alcuni
aminoacidi sono codificati da più triplette.
Per quanto riguarda
la densità informativa considerate che una cellula umana contiene poco più
di 6 picogrammi di DNA (diploide, cioè in doppia copia, ciascuna delle quali originata da un genitore) Di questi in realtà solo l'1,6% è codificante; sebbene un tempo si ipotizzasse che tutto il resto del DNA avesse solo un ruolo strutturale o di "parafulmine" (in cui era più facile che le mutazioni avvenissero lasciando inalterato la parte "utile"), questa idea è stata ampiamente ridimensionata negli ultimi anni grazie alla scoperta del suo ruolo nella regolazione dell'espressione genica (se, quando e dove un dato gene deve essere espresso). Tuttavia per semplificare al massimo il concetto e prendendo per buona la vecchia idea che solo l'1,6% del genoma è utile e dividendolo a metà (genoma aploide, cioè una sola copia di ciascun gene) potrei dire che il nostro "programma" è contenuto in 52 femtogrammi di DNA. Pensate per contrasto quanto "codice" e memoria fisica ci vuole per muovere un robottino capace solo di fare due passi.
Nota 3. Oltre agli errori di lettura bisogna considerare anche le
alterazioni a cui il pur stabile DNA può andare incontro con il passare
del tempo,
Nota 4. Altro problema è nella non
"neutralità" dell'informazione scritta sul DNA rispetto a quella
digitale. Per capirci ipotizzando l'associazione C-01 e G-10, non c'è
alcun problema in un file 010101010101101010101010. Tuttavia l'analogo
CCCCCCGGGGGG (o ogni altra sequenza ricca di CG) pone problemi
strutturali a causa della formazione di "forcine per l'appaiamento tra C
e G. Stesso discorso per qualunque DNA con lunghe sequenze di
nucleotidi identici che pongono un problema in fase di lettura (e anche copiatura/sintesi) noto come "slippage" (scivolamento dell'enzima
deputato) che porta alla perdita/aggiunta di nucleotidi e quindi alla
modifica dell'informazione
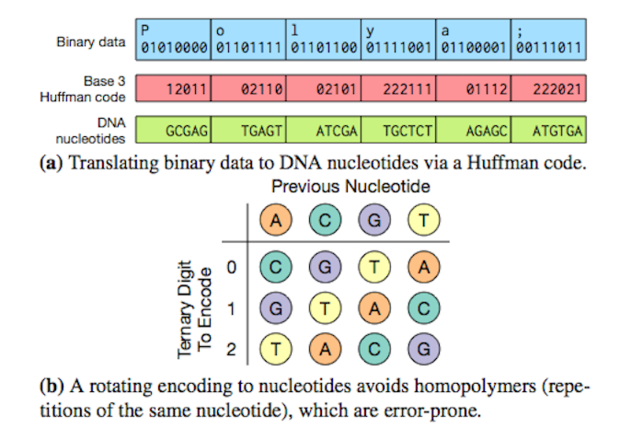
Un modo per evitare la creazione di sequenze ripetute di uno stesso nucleotide (quindi il rischio di "slippage") è quello di usare prima un passaggio intermedio nella codifica da binario a DNA mediante il codice di Huffman e poi una codifica variabile ma predefinita. (credit: University of Washington via computerworld.com)
"Un libro non merita di essere letto a 10 anni se non merita di essere letto anche a 50" Clive S. Lewis
"Il concetto di probabilità è il più importante della scienza moderna, soprattutto perché nessuno ha la più pallida idea del suo significato" Bertrand Russel
"La nostra conoscenza può essere solo finita, mentre la nostra ignoranza deve essere necessariamente infinita" Karl Popper